As commented in my last post, CLEFIA implementation in Python, the performance figures for key setup and block encryption of my first coding attempt were poor when compared to those of AES.
Nevertheless, in order to establish a fair comparison between the two implementations, I included in CLEFIA’s code the same optimization technique used in AES, memoization, for speeding up the multiplication in the binary finite field GF(2^8). For this purpose, the generic multiplication function used in the first version was replaced by five memoized functions, x2(), x4(), x6(), x8() and x10(), thanks to the fact that there are only five different constants (besides the multiplicative identity of the field, 1) in the matrices m0 and m1.
The payback of this small effort was remarkable: the new code is 7 times(!) faster than the old, as the time required for the 128-bit key setup plus block encryption (in ECB mode) went down from 3.8 ms to 0.5 ms. A similar reduction was observed for 192- and 256-bit keys: from 5.2ms to 0.7 ms and 5.7 ms to 0.77 ms. All numbers were observed in a Core i7-2600K @ 3.5 GHz desktop running 64-bit Windows 7. The Python interpreter used was ActivePython-3.2.2.3-win64-x64.
#!/usr/bin/python3
#
# Author: Joao H de A Franco (jhafranco@acm.org)
#
# Description: CLEFIA implementation in Python 3
#
# Date: 2012-02-03
#
# License: Attribution-NonCommercial-ShareAlike 3.0 Unported
# (CC BY-NC-SA 3.0)
#===========================================================
import sys
from time import time
# Key sizes supported
ksTable = {"SIZE_128": 16,
"SIZE_192": 24,
"SIZE_256": 32}
# Number of rounds related to key size
nrTable = {"SIZE_128": 18,
"SIZE_192": 22,
"SIZE_256": 26}
# Number of round keys related to key size
nrkTable = {"SIZE_128": 36,
"SIZE_192": 44,
"SIZE_256": 52}
# Number of rounds
nr = None
# Number of round keys effectively used
nrk = None
# Number of whitening keys
nwk = 4
# Round keys vector
rk = [None] * 2 * nrTable[max(nrTable)]
# Whitening keys
wk = [None] * 4
# First S-Box
s0 = [0x57, 0x49, 0xd1, 0xc6, 0x2f, 0x33, 0x74, 0xfb,
0x95, 0x6d, 0x82, 0xea, 0x0e, 0xb0, 0xa8, 0x1c,
0x28, 0xd0, 0x4b, 0x92, 0x5c, 0xee, 0x85, 0xb1,
0xc4, 0x0a, 0x76, 0x3d, 0x63, 0xf9, 0x17, 0xaf,
0xbf, 0xa1, 0x19, 0x65, 0xf7, 0x7a, 0x32, 0x20,
0x06, 0xce, 0xe4, 0x83, 0x9d, 0x5b, 0x4c, 0xd8,
0x42, 0x5d, 0x2e, 0xe8, 0xd4, 0x9b, 0x0f, 0x13,
0x3c, 0x89, 0x67, 0xc0, 0x71, 0xaa, 0xb6, 0xf5,
0xa4, 0xbe, 0xfd, 0x8c, 0x12, 0x00, 0x97, 0xda,
0x78, 0xe1, 0xcf, 0x6b, 0x39, 0x43, 0x55, 0x26,
0x30, 0x98, 0xcc, 0xdd, 0xeb, 0x54, 0xb3, 0x8f,
0x4e, 0x16, 0xfa, 0x22, 0xa5, 0x77, 0x09, 0x61,
0xd6, 0x2a, 0x53, 0x37, 0x45, 0xc1, 0x6c, 0xae,
0xef, 0x70, 0x08, 0x99, 0x8b, 0x1d, 0xf2, 0xb4,
0xe9, 0xc7, 0x9f, 0x4a, 0x31, 0x25, 0xfe, 0x7c,
0xd3, 0xa2, 0xbd, 0x56, 0x14, 0x88, 0x60, 0x0b,
0xcd, 0xe2, 0x34, 0x50, 0x9e, 0xdc, 0x11, 0x05,
0x2b, 0xb7, 0xa9, 0x48, 0xff, 0x66, 0x8a, 0x73,
0x03, 0x75, 0x86, 0xf1, 0x6a, 0xa7, 0x40, 0xc2,
0xb9, 0x2c, 0xdb, 0x1f, 0x58, 0x94, 0x3e, 0xed,
0xfc, 0x1b, 0xa0, 0x04, 0xb8, 0x8d, 0xe6, 0x59,
0x62, 0x93, 0x35, 0x7e, 0xca, 0x21, 0xdf, 0x47,
0x15, 0xf3, 0xba, 0x7f, 0xa6, 0x69, 0xc8, 0x4d,
0x87, 0x3b, 0x9c, 0x01, 0xe0, 0xde, 0x24, 0x52,
0x7b, 0x0c, 0x68, 0x1e, 0x80, 0xb2, 0x5a, 0xe7,
0xad, 0xd5, 0x23, 0xf4, 0x46, 0x3f, 0x91, 0xc9,
0x6e, 0x84, 0x72, 0xbb, 0x0d, 0x18, 0xd9, 0x96,
0xf0, 0x5f, 0x41, 0xac, 0x27, 0xc5, 0xe3, 0x3a,
0x81, 0x6f, 0x07, 0xa3, 0x79, 0xf6, 0x2d, 0x38,
0x1a, 0x44, 0x5e, 0xb5, 0xd2, 0xec, 0xcb, 0x90,
0x9a, 0x36, 0xe5, 0x29, 0xc3, 0x4f, 0xab, 0x64,
0x51, 0xf8, 0x10, 0xd7, 0xbc, 0x02, 0x7d, 0x8e]
# Second S-Box
s1 = [0x6c, 0xda, 0xc3, 0xe9, 0x4e, 0x9d, 0x0a, 0x3d,
0xb8, 0x36, 0xb4, 0x38, 0x13, 0x34, 0x0c, 0xd9,
0xbf, 0x74, 0x94, 0x8f, 0xb7, 0x9c, 0xe5, 0xdc,
0x9e, 0x07, 0x49, 0x4f, 0x98, 0x2c, 0xb0, 0x93,
0x12, 0xeb, 0xcd, 0xb3, 0x92, 0xe7, 0x41, 0x60,
0xe3, 0x21, 0x27, 0x3b, 0xe6, 0x19, 0xd2, 0x0e,
0x91, 0x11, 0xc7, 0x3f, 0x2a, 0x8e, 0xa1, 0xbc,
0x2b, 0xc8, 0xc5, 0x0f, 0x5b, 0xf3, 0x87, 0x8b,
0xfb, 0xf5, 0xde, 0x20, 0xc6, 0xa7, 0x84, 0xce,
0xd8, 0x65, 0x51, 0xc9, 0xa4, 0xef, 0x43, 0x53,
0x25, 0x5d, 0x9b, 0x31, 0xe8, 0x3e, 0x0d, 0xd7,
0x80, 0xff, 0x69, 0x8a, 0xba, 0x0b, 0x73, 0x5c,
0x6e, 0x54, 0x15, 0x62, 0xf6, 0x35, 0x30, 0x52,
0xa3, 0x16, 0xd3, 0x28, 0x32, 0xfa, 0xaa, 0x5e,
0xcf, 0xea, 0xed, 0x78, 0x33, 0x58, 0x09, 0x7b,
0x63, 0xc0, 0xc1, 0x46, 0x1e, 0xdf, 0xa9, 0x99,
0x55, 0x04, 0xc4, 0x86, 0x39, 0x77, 0x82, 0xec,
0x40, 0x18, 0x90, 0x97, 0x59, 0xdd, 0x83, 0x1f,
0x9a, 0x37, 0x06, 0x24, 0x64, 0x7c, 0xa5, 0x56,
0x48, 0x08, 0x85, 0xd0, 0x61, 0x26, 0xca, 0x6f,
0x7e, 0x6a, 0xb6, 0x71, 0xa0, 0x70, 0x05, 0xd1,
0x45, 0x8c, 0x23, 0x1c, 0xf0, 0xee, 0x89, 0xad,
0x7a, 0x4b, 0xc2, 0x2f, 0xdb, 0x5a, 0x4d, 0x76,
0x67, 0x17, 0x2d, 0xf4, 0xcb, 0xb1, 0x4a, 0xa8,
0xb5, 0x22, 0x47, 0x3a, 0xd5, 0x10, 0x4c, 0x72,
0xcc, 0x00, 0xf9, 0xe0, 0xfd, 0xe2, 0xfe, 0xae,
0xf8, 0x5f, 0xab, 0xf1, 0x1b, 0x42, 0x81, 0xd6,
0xbe, 0x44, 0x29, 0xa6, 0x57, 0xb9, 0xaf, 0xf2,
0xd4, 0x75, 0x66, 0xbb, 0x68, 0x9f, 0x50, 0x02,
0x01, 0x3c, 0x7f, 0x8d, 0x1a, 0x88, 0xbd, 0xac,
0xf7, 0xe4, 0x79, 0x96, 0xa2, 0xfc, 0x6d, 0xb2,
0x6b, 0x03, 0xe1, 0x2e, 0x7d, 0x14, 0x95, 0x1d]
m0 = [0x01, 0x02, 0x04, 0x06, 0x02, 0x01, 0x06, 0x04,
0x04, 0x06, 0x01, 0x02, 0x06, 0x04, 0x02, 0x01]
m1 = [0x01, 0x08, 0x02, 0x0a, 0x08, 0x01, 0x0a, 0x02,
0x02, 0x0a, 0x01, 0x08, 0x0a, 0x02, 0x08, 0x01]
con128 = [0xf56b7aeb, 0x994a8a42, 0x96a4bd75, 0xfa854521,
0x735b768a, 0x1f7abac4, 0xd5bc3b45, 0xb99d5d62,
0x52d73592, 0x3ef636e5, 0xc57a1ac9, 0xa95b9b72,
0x5ab42554, 0x369555ed, 0x1553ba9a, 0x7972b2a2,
0xe6b85d4d, 0x8a995951, 0x4b550696, 0x2774b4fc,
0xc9bb034b, 0xa59a5a7e, 0x88cc81a5, 0xe4ed2d3f,
0x7c6f68e2, 0x104e8ecb, 0xd2263471, 0xbe07c765,
0x511a3208, 0x3d3bfbe6, 0x1084b134, 0x7ca565a7,
0x304bf0aa, 0x5c6aaa87, 0xf4347855, 0x9815d543,
0x4213141a, 0x2e32f2f5, 0xcd180a0d, 0xa139f97a,
0x5e852d36, 0x32a464e9, 0xc353169b, 0xaf72b274,
0x8db88b4d, 0xe199593a, 0x7ed56d96, 0x12f434c9,
0xd37b36cb, 0xbf5a9a64, 0x85ac9b65, 0xe98d4d32,
0x7adf6582, 0x16fe3ecd, 0xd17e32c1, 0xbd5f9f66,
0x50b63150, 0x3c9757e7, 0x1052b098, 0x7c73b3a7]
con192 = [0xc6d61d91, 0xaaf73771, 0x5b6226f8, 0x374383ec,
0x15b8bb4c, 0x799959a2, 0x32d5f596, 0x5ef43485,
0xf57b7acb, 0x995a9a42, 0x96acbd65, 0xfa8d4d21,
0x735f7682, 0x1f7ebec4, 0xd5be3b41, 0xb99f5f62,
0x52d63590, 0x3ef737e5, 0x1162b2f8, 0x7d4383a6,
0x30b8f14c, 0x5c995987, 0x2055d096, 0x4c74b497,
0xfc3b684b, 0x901ada4b, 0x920cb425, 0xfe2ded25,
0x710f7222, 0x1d2eeec6, 0xd4963911, 0xb8b77763,
0x524234b8, 0x3e63a3e5, 0x1128b26c, 0x7d09c9a6,
0x309df106, 0x5cbc7c87, 0xf45f7883, 0x987ebe43,
0x963ebc41, 0xfa1fdf21, 0x73167610, 0x1f37f7c4,
0x01829338, 0x6da363b6, 0x38c8e1ac, 0x54e9298f,
0x246dd8e6, 0x484c8c93, 0xfe276c73, 0x9206c649,
0x9302b639, 0xff23e324, 0x7188732c, 0x1da969c6,
0x00cd91a6, 0x6cec2cb7, 0xec7748d3, 0x8056965b,
0x9a2aa469, 0xf60bcb2d, 0x751c7a04, 0x193dfdc2,
0x02879532, 0x6ea666b5, 0xed524a99, 0x8173b35a,
0x4ea00d7c, 0x228141f9, 0x1f59ae8e, 0x7378b8a8,
0xe3bd5747, 0x8f9c5c54, 0x9dcfaba3, 0xf1ee2e2a,
0xa2f6d5d1, 0xced71715, 0x697242d8, 0x055393de,
0x0cb0895c, 0x609151bb, 0x3e51ec9e, 0x5270b089]
con256 = [0x0221947e, 0x6e00c0b5, 0xed014a3f, 0x8120e05a,
0x9a91a51f, 0xf6b0702d, 0xa159d28f, 0xcd78b816,
0xbcbde947, 0xd09c5c0b, 0xb24ff4a3, 0xde6eae05,
0xb536fa51, 0xd917d702, 0x62925518, 0x0eb373d5,
0x094082bc, 0x6561a1be, 0x3ca9e96e, 0x5088488b,
0xf24574b7, 0x9e64a445, 0x9533ba5b, 0xf912d222,
0xa688dd2d, 0xcaa96911, 0x6b4d46a6, 0x076cacdc,
0xd9b72353, 0xb596566e, 0x80ca91a9, 0xeceb2b37,
0x786c60e4, 0x144d8dcf, 0x043f9842, 0x681edeb3,
0xee0e4c21, 0x822fef59, 0x4f0e0e20, 0x232feff8,
0x1f8eaf20, 0x73af6fa8, 0x37ceffa0, 0x5bef2f80,
0x23eed7e0, 0x4fcf0f94, 0x29fec3c0, 0x45df1f9e,
0x2cf6c9d0, 0x40d7179b, 0x2e72ccd8, 0x42539399,
0x2f30ce5c, 0x4311d198, 0x2f91cf1e, 0x43b07098,
0xfbd9678f, 0x97f8384c, 0x91fdb3c7, 0xfddc1c26,
0xa4efd9e3, 0xc8ce0e13, 0xbe66ecf1, 0xd2478709,
0x673a5e48, 0x0b1bdbd0, 0x0b948714, 0x67b575bc,
0x3dc3ebba, 0x51e2228a, 0xf2f075dd, 0x9ed11145,
0x417112de, 0x2d5090f6, 0xcca9096f, 0xa088487b,
0x8a4584b7, 0xe664a43d, 0xa933c25b, 0xc512d21e,
0xb888e12d, 0xd4a9690f, 0x644d58a6, 0x086cacd3,
0xde372c53, 0xb216d669, 0x830a9629, 0xef2beb34,
0x798c6324, 0x15ad6dce, 0x04cf99a2, 0x68ee2eb3]
def _8To32(x32):
"""Convert a 4-byte list to a 32-bit integer"""
return (((((x32[0] << 8) + x32[1]) << 8) + x32[2]) << 8) + x32[3]
def _32To8(x32):
"""Convert a 32-bit integer to a 4-byte list"""
return [(x32 >> 8 * i) & 0xff for i in reversed(range(4))]
def _32To128(x32):
"""Convert a 32-bit 4-element list to a 128-bit integer"""
return (((((x32[0] << 32) + x32[1]) << 32) + x32[2]) << 32) + x32[3]
def _128To32(x128):
"""Convert a 128-bit integer to a 32-bit 4-element list"""
return [(x128 >> 32 * i) & 0xffffffff for i in reversed(range(4))]
def _192To32(x192):
"""Convert a 192-bit integer to a 32-bit 6-element list"""
return [(x192 >> 32 * i) & 0xffffffff for i in reversed(range(6))]
def _256To32(x256):
"""Convert a 256-bit integer to a 32-bit 8-element list"""
return [(x256 >> 32 * i) & 0xffffffff for i in reversed(range(8))]
def sigma(x128):
"""The double-swap function sigma (used in key scheduling)"""
return [(x128[0] << 7) & 0xffffff80 | (x128[1] >> 25),
(x128[1] << 7) & 0xffffff80 | (x128[3] & 0x7f),
(x128[0] & 0xfe000000) | (x128[2] >> 7),
(x128[2] << 25) & 0xfe000000 | (x128[3] >> 7)]
def memoize(f):
"""Memoization function"""
memo = {}
def helper(x):
if x not in memo:
memo[x] = f(x)
return memo[x]
return helper
def mult(p1, p2):
"""Multiply two polynomials in GF(2^8)
(the irreducible polynomial used in this
field is x^8 + x^4 + x^3 + x^2 + 1)"""
p = 0
while p2:
if p2 & 0b1:
p ^= p1
p1 <<= 1
if p1 & 0x100:
p1 ^= 0b11101
p2 >>= 1
return p & 0xff
# Auxiliary one-parameter functions defined for memoization
# (to speed up multiplication in GF(2^8))
@memoize
def x2(y):
"""Multiply by 2 in GF(2^8)"""
return mult(2, y)
@memoize
def x4(y):
"""Multiply by 4 in GF(2^8)"""
return mult(4, y)
@memoize
def x6(y):
"""Multiply by 6 in GF(2^8)"""
return mult(6, y)
@memoize
def x8(y):
"""Multiply by 8 in GF(2^8)"""
return mult(8, y)
@memoize
def x10(y):
"""Multiply by 10 in GF(2^8)"""
return mult(10, y)
def multm0(t32):
"""Multiply the matrix m0 by a 4-element transposed vector in GF(2^8)"""
return [ t32[0] ^ x2(t32[1]) ^ x4(t32[2]) ^ x6(t32[3]),
x2(t32[0]) ^ t32[1] ^ x6(t32[2]) ^ x4(t32[3]),
x4(t32[0]) ^ x6(t32[1]) ^ t32[2] ^ x2(t32[3]),
x6(t32[0]) ^ x4(t32[1]) ^ x2(t32[2]) ^ t32[3]]
def multm1(t32):
"""Multiply the matrix m1 by a 4-element transposed vector in GF(2^8)"""
return [ t32[0] ^ x8(t32[1]) ^ x2(t32[2]) ^ x10(t32[3]),
x8(t32[0]) ^ t32[1] ^ x10(t32[2]) ^ x2(t32[3]),
x2(t32[0]) ^ x10(t32[1]) ^ t32[2] ^ x8(t32[3]),
x10(t32[0]) ^ x2(t32[1]) ^ x8(t32[2]) ^ t32[3]]
def f0(rk, x32):
"""F0 function"""
t8 = _32To8(rk ^ x32)
t8 = [s0[t8[0]], s1[t8[1]], s0[t8[2]], s1[t8[3]]]
return _8To32(multm0(t8))
def f1(rk, x32):
"""F1 function"""
t8 = _32To8(rk ^ x32)
t8 = s1[t8[0]], s0[t8[1]], s1[t8[2]], s0[t8[3]]
return _8To32(multm1(t8))
def gfn4(x32, n):
"""4-branch Generalized Feistel Network function"""
t32 = x32[:]
for i in range(0, n << 1, 2):
t32[1] ^= f0(rk[i], t32[0])
t32[3] ^= f1(rk[i + 1], t32[2])
t32 = t32[1:] + t32[:1]
return t32[3:] + t32[:3]
def gfn4i(x32, n):
"""4-branch Generalized Feistel Network inverse function"""
t32 = x32[:]
for i in reversed(range(0, n << 1, 2)):
t32[1] ^= f0(rk[i], t32[0])
t32[3] ^= f1(rk[i + 1], t32[2])
t32 = t32[3:] + t32[:3]
return t32[1:] + t32[:1]
def gfn8(x32, n):
"""8-branch Generalized Feistel Network function"""
t32 = x32[:]
for i in range(0, n << 2, 4):
t32[1] ^= f0(rk[i], t32[0])
t32[3] ^= f1(rk[i + 1], t32[2])
t32[5] ^= f0(rk[i + 2], t32[4])
t32[7] ^= f1(rk[i + 3], t32[6])
t32 = t32[1:] + t32[:1]
return t32[7:] + t32[:7]
def setKey128(k128):
"""Generate round/whitening keys from a 128-bit key"""
k32 = _128To32(k128)
for i in range(len(con128) - nrk):
rk[i] = con128[i]
l = gfn4(k32, 12)
for i in range(nwk):
wk[i] = k32[i]
for i in range(0, nrk, 4):
t32 = [r ^ s for r, s in zip(l, con128[i + 24:i + 28])]
l = sigma(l)
if i & 0b100:
rk[i:i + 4] = [r ^ s for r, s in zip(t32, k32)]
else:
rk[i:i + 4] = t32
def setKey192(k192):
"""Generate round/whitening keys from a 192-bit key"""
k32 = _192To32(k192)
kl = k32[:4]
kr = k32[4:6] + [k32[0] ^ 0xffffffff] + [k32[1] ^ 0xffffffff]
for i in range(len(con192) - nrk):
rk[i] = con192[i]
l = gfn8(kl + kr, 10)
ll, lr = l[:4], l[4:]
kk = [r ^ s for r, s in zip(kl, kr)]
for i in range(nwk):
wk[i] = kk[i]
for i in range(0, nrk, 4):
if i & 0b1100 < 8:
t32 = [r ^ s for r, s in zip(ll, con192[i + 40:i + 44])]
ll = sigma(ll)
if i & 0b100:
t32 = [r ^ s for r, s in zip(t32, kr)]
else:
t32 = [r ^ s for r, s in zip(lr, con192[i + 40:i + 44])]
lr = sigma(lr)
if i & 0b100:
t32 = [r ^ s for r, s in zip(t32, kl)]
rk[i:i + 4] = t32
def setKey256(k256):
"""Generate round/whitening keys from a 256-bit key"""
k32 = _256To32(k256)
kl, kr = k32[:4], k32[4:]
for i in range(len(con256) - nrk):
rk[i] = con256[i]
l = gfn8(kl + kr, 10)
ll, lr = l[:4], l[4:]
kk = [r ^ s for r, s in zip(kl, kr)]
for i in range(nwk):
wk[i] = kk[i]
for i in range(0, nrk, 4):
if i & 0b1100 < 8:
t32 = [r ^ s for r, s in zip(ll, con256[i + 40:i + 44])]
ll = sigma(ll)
if i & 0b100:
t32 = [r ^ s for r, s in zip(t32, kr)]
else:
t32 = [r ^ s for r, s in zip(lr, con256[i + 40:i + 44])]
lr = sigma(lr)
if i & 0b100:
t32 = [r ^ s for r, s in zip(t32, kl)]
rk[i:i + 4] = t32
def setKey(key, keySize):
"""Generate round/whitening keys from the given key"""
global nr, nrk
try:
assert keySize in ksTable
except AssertionError:
print("Key size identifier not valid")
sys.exit("ValueError")
try:
assert isinstance(key, int)
except AssertionError:
print("Invalid key")
sys.exit("ValueError")
try:
assert key.bit_length() // 8 <= ksTable[keySize]
except AssertionError:
print("Key size mismatch")
sys.exit("ValueError")
nr = nrTable[keySize]
nrk = nrkTable[keySize]
if keySize == "SIZE_128":
setKey128(key)
elif keySize == "SIZE_192":
setKey192(key)
elif keySize == "SIZE_256":
setKey256(key)
else:
sys.exit("Invalid key size identifier")
def encrypt(ptext):
"""Encrypt a block"""
t32 = _128To32(ptext)
t32[1] ^= wk[0]
t32[3] ^= wk[1]
t32 = gfn4(t32, nr)
t32[1] ^= wk[2]
t32[3] ^= wk[3]
return _32To128(t32)
def decrypt(ctext):
"""Decrypt a block"""
t32 = _128To32(ctext)
t32[1] ^= wk[2]
t32[3] ^= wk[3]
t32 = gfn4i(t32, nr)
t32[1] ^= wk[0]
t32[3] ^= wk[1]
return _32To128(t32)
if __name__ == "__main__":
def checkTestVector(key, keySize, plaintext, ciphertext, nIter = 1000):
testSuccess = True
setKey(key, keySize)
ks = ksTable[keySize] * 8
ctext = encrypt(plaintext)
ptext = decrypt(ctext)
try:
assert ctext == ciphertext
except AssertionError:
print("Error in encryption")
print("Resulting ciphertext: {:02x}".format(ctext))
print("Expected ciphertext: {:02x}".format(ciphertext))
testSuccess = False
try:
assert ptext == plaintext
except AssertionError:
print("Error in decryption:")
print("Recovered plaintext: {:02x}".format(ptext))
print("Expected plaintext: {:02x}".format(plaintext))
testSuccess = False
if not testSuccess:
return False
t1 = time()
for i in range(nIter):
setKey(key, keySize)
ctext = encrypt(plaintext)
t2 = time()
avg_elapsed_time = (t2 - t1) * 1000 / nIter
print("{:3d}-bit key test ok!".format(ksTable[keySize] * 8))
print("Average elapsed time for 16-byte block ", end="")
print("ECB-{0:3d} encryption: {1:0.3f}ms".format(ks, avg_elapsed_time))
t3 = time()
for i in range(nIter):
setKey(key, keySize)
ptext = decrypt(ctext)
t4 = time()
avg_elapsed_time = (t4 - t3) * 1000 / nIter
print("{:3d}-bit key test ok!".format(ksTable[keySize] * 8))
print("Average elapsed time for 16-byte block ", end="")
print("ECB-{0:3d} decryption: {1:0.3f}ms".format(ks, avg_elapsed_time))
return True
# The test vectors below are described in document "The 128-bit Blockcipher
# CLEFIA Algorithm Specification" rev.1, June 1, 2007, Sony Corporation.
ptext = 0x000102030405060708090a0b0c0d0e0f
# Test vector for 128-bit key
key1 = 0xffeeddccbbaa99887766554433221100
ctext1 = 0xde2bf2fd9b74aacdf1298555459494fd
# Test vector for 192-bit key
key2 = 0xffeeddccbbaa99887766554433221100f0e0d0c0b0a09080
ctext2 = 0xe2482f649f028dc480dda184fde181ad
# Test vector for 256-bit key
key3 = 0xffeeddccbbaa99887766554433221100f0e0d0c0b0a090807060504030201000
ctext3 = 0xa1397814289de80c10da46d1fa48b38a
try:
assert checkTestVector(key1, "SIZE_128", ptext, ctext1) and \
checkTestVector(key2, "SIZE_192", ptext, ctext2) and \
checkTestVector(key3, "SIZE_256", ptext, ctext3)
except AssertionError:
print("At least one test failed")
sys.exit(1)
print("All tests passed!")
sys.exit()

 . The second function,
. The second function,  .
.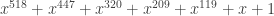 and
and  is:
is: (which happens to be the Mersenne prime # 14), we get the following results:
(which happens to be the Mersenne prime # 14), we get the following results: